【データ分析】ゼロからわかるデータドリブン入門!

情報化社会の発展により、各業界でビッグデータの需要が高まる昨今。当社ブルームテクノロジーでも各種データの活用に日々チャレンジしております。そうしたビッグデータを活用する際に重要とされるのが「データドリブン」といった業務プロセスです。
マーケティング分析などでこの「データドリブン」がよく活用されておりますが、AI業務を担当する当社でも「データドリブン」のプロセスを大切にしております。
そこで今回は、AI業務の視点から「データドリブン」とはどのようなものかをご紹介させていただきます。
データドリブンとは?
データドリブンとは、データ収集と分析を繰り返しながら、データを軸に意思決定の最適化、およびそれに伴ったアクションを実行する業務プロセスを指します。
【データドリブンの例】スーパーマーケットの3ステップ
① 品薄や売れ残りが比較的多い商品をピックアップ
② 1週(カ月)間の売上データを集計、各商品の売上量やトレンドを確認
③ データに基づいて、次回仕入れ商品の最適な種類と量を決定
上記3ステップを繰り返すことで、理想と現実のギャップをデータ(数値)で確認し、売上向上とロス削減を効率的に行うことができます。
つまり、ビジネスの中で生じる理想と現実のギャップを埋めるために、データを軸に試行錯誤するプロセスこそが「データドリブン」といえます。
データドリブンの必要性
次に、データドリブンの必要性について、データに基づいて意思決定やアクションを行うメリットも含めご紹介します。
データドリブンには以下のようなメリットがあります。
- 発展性が高い
- 再現性が高い
- 客観性を保てる
上記のメリットについて、「経験や勘による意思決定やアクションの実行」との比較を通した具体的な説明が以下となります。
| 経験・勘 | データドリブン | |
| 発展性 | 「なぜ上手くいったのか?なぜ失敗したのか?」の要因が暗黙知の場合が多く、不透明になりがち。 結果、根拠なき暗中模索を繰り返してしまうことが多い。 | データを確認することで「この施策は〇〇だから成功・失敗した」などの要因の理解がしやすい。 結果、改善点の洗い出し・ブラッシュアップが比較的簡単。 |
| 再現性 | 他者に共有しにくい情報や個人的な感覚が大きなウェイトを占めるため、同じことをやっても人によって成果のバラツキがでやすい。 | 成功・失敗の要因やプロセスを形式知として、明確にするため、誰がやっても同じ成果を再現しやすい。 |
| 客観性 | 個人的な考えや判断になりがちで、信頼性の担保が難しい。 | データ(数値)は、客観的な事実であるため、信憑性が担保される。 |
「経験・勘」のみに頼り切ってしまうと、上記のように「発展性・再現性・客観性」を担保することが難しくなります。そこで「データドリブン + 経験・勘」の双方を意識することで、ビジネスのトライアンドエラーの質を高めることにつながります。
データドリブンの流れや留意点
データドリブンを実現するには、基本的に以下の流れが求められます。
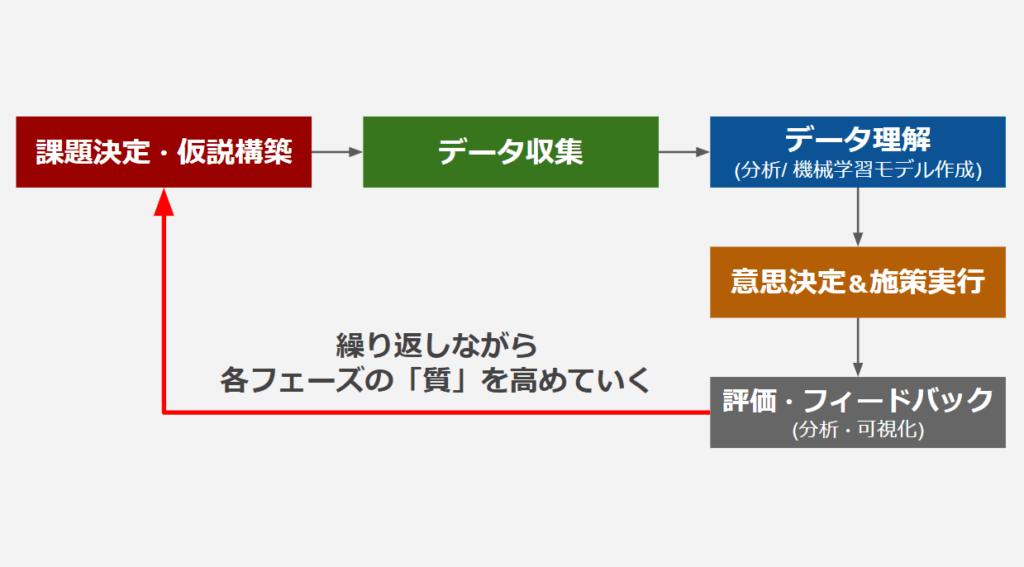
各フェーズごとの留意点
データドリブンの流れや各フェーズにおける注意する点は以下となります。
① 課題設定 & 仮説構築
まずデータドリブンの前提として、初めに現状の課題、及びデータ分析のゴールの設定を行います。ここでのゴールとは「到達すべき地点」を指し、課題とは「ゴールに到達するために必要なアクション」を意味します。
▼【ゴール】&【課題】の例
ゴール:来月の売上N%UP
課題 :販促PRのターゲット選定の為、顧客データから優良顧客の属性(年齢・職業・家族構成 等)を抽出
基本的にゴールは1つですが、ゴールのための課題候補は複数ある状況が考えられます。そうした場合は、ゴールを見据えた上での深い仮説構築をし、より確度の高い課題を複数候補としながらデータ分析の過程で絞り込んでいきます。
② データ収集
データ収集とは、上記①で設定した課題・仮説に対して「適切なデータ」を収集することを意味します。
前提として、「適切なデータ」とは単に大量のデータを指しません。「大量のデータがあればデータドリブンはうまくいく」と考えられがちですが、そこには注意が必要です。どんなに大量のデータがあっても、課題に対して適切な要素が含まれていないデータは欠落データとなります。
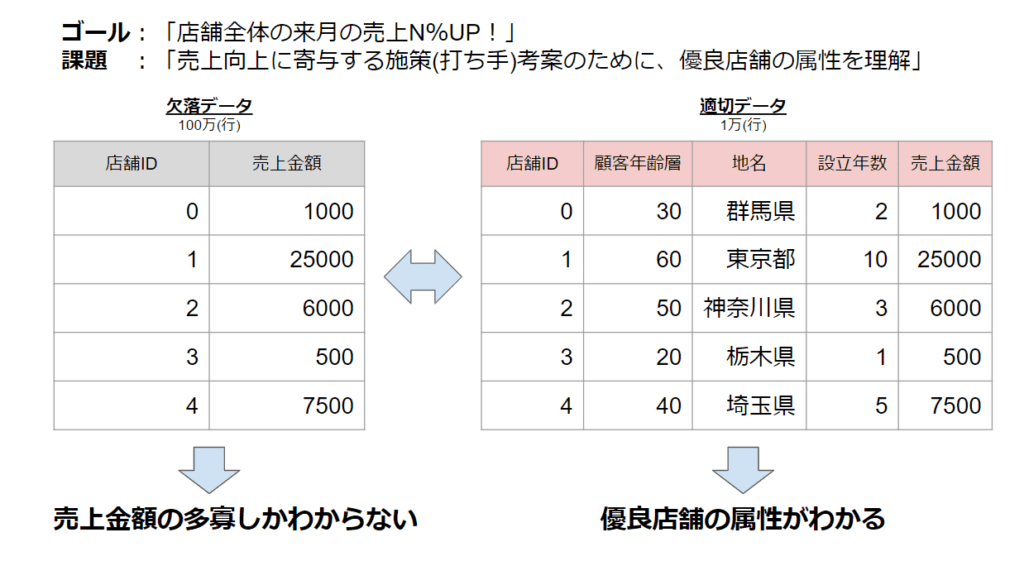
図2は、課題(優良店舗の特徴抽出)に対して分析を行なうケースを想定した内容です。少々極端な例ですが、欠落データからは売上金額が高い店舗は判明しても、その要因、つまり優良店舗が持つ特徴・属性まではわかりません。
つまり、適切なデータを集める前にデータ分析を始めたとしても、間違った解釈をしてしまうか、答えの出ないデータ分析を延々と繰り返してしまう恐れがあります。
データ分析に着手する前に、分析を行おうとしているデータ自体が、課題に対して適切なっものか、それとも追加のデータ収集が必要なのかを注意深く判断する必要があります。
※「ガーベッジイン・ガーベッジアウト」の鉄則
データ活用において、どれだけ大量のデータを使っても適切なデータでなければ、全く役に立たないことを意味しています。参考:ウィキペディア
③ データ理解 (分析・機械学習モデル作成・可視化)
データ理解では、上部①(課題設定 & 仮説構築)で設定した仮説検証のためのデータ分析・機械学習モデルの作成・可視化を行います。当フェーズの注意点ですが、データの持つ膨大な情報量や多種多様な手法にとらわれてしまい、当初のゴールや検証すべき内容からズレた分析を行ってしまうことです。
データ分析・AIブームである昨今において「とりあえず機械学習(ディープラーニング)を取り入れればすごい結果が出るでしょ」といった状況が散見されます。
本来、機械学習(ディープラーニング)を使う必要がない、もしくは使うのに適していないデータや課題に対して、無理にそれらを用いてしまうことは、時間・資金共に大幅な損失が生じてしまう恐れがあります。場合によっては、統計手法は用いずに単純な集計が有効となることも多々あります。
常にゴールと課題を見据えながら、手法やツール選択を行っていくことが重要となります。
④ 意思決定・施策実行
上記①~③を見定めた後に、いよいよ意思決定・施策実行を行っていきます。
データを基点とした質の高い意思決定・施策実行を目指すことになりますが、データを活用するにあたって忘れてはいけないことがあります。それは、データは事象の一面を切り取ったものに過ぎず、常に「潜在的な不確実性」と「欠落性」を孕んでいるということです。
意思決定・施策実行のフェーズにおいて、データ分析の結果と直感・経験が噛み合わないケースが多々ありますが、そうした場合にデータを盲信しすぎるのは危険です。どんなに高性能なAIや優れた分析であっても、常に潜在的な不確実性と欠落性からは逃れられません。そうした事実を認識した上で、データ分析の結果 + 直感・経験をベースにした決断も重要となります。
⑤ 施策評価・フィードバック(分析・可視化)
当フェーズでは、上部④で行った意思決定・施策実行に対して「評価・フィードバック」に向けた分析・可視化を行っていきます。
施策実行の結果に対して、適切な評価を行うための分析・可視化を行うことはもちろんですが、その上でその次の課題設定 & 仮説構築(上部①)につながる内容であることが求められます。
即ち、データドリブンの一連のフェーズを通して得た知見やデータを、次回のより質の高い課題設定 & 仮説構築に繋げることも必要であり、重要なポイントです。
まとめ:データドリブンこと始め
AI視点での「データドリブン」についていかがでしたでしょうか。
データドリブンを始めたての頃は、そもそもサイクルがうまく回らなかったり、回ったとしても結果に繋がらないことは珍しくありません。また、データ分析の環境構築や組織的要因、AI活用が持つ不確実性などが相成って、データドリブン自体が組織に浸透するのに時間やコストがかかってしまう場合があります。
そういったことを認識した上で、初めは小さなゴールや課題を設定し、少しずつトライアンドエラーを繰り返すことが大切なポイントとなります。データドリブンのサイクルを回しながら質・経験も少しずつ高めていくことが、サービスやプロジェクト成功へのカギとなっていくことでしょう。
当社の技術ブログ第一弾ということで、データ活用・分析の基盤となるプロセスである「データドリブン」についてご紹介させていただきました。データ分析などを担当されている方々の参考となれたら嬉しい限りです。



