kaggleレコメンドコンペティションに挑戦

はじめに
こんにちは。データサイエンス課 ブログ担当です。
今年3月に社内研修の一環として『kaggle(カグル) H&Mコンペティション』に挑戦しました。
コンペ内容としては、アパレルメーカーH&Mの商品レコメンドに関するもので、 平常業務内の2h/日 程を割り当て参加しました。
社内でもレコメンドプロジェクトが進行していたこともあり、コンペティション参加によって培ったナレッジの提供をしたいといったことも、当コンペを選定した経緯となります。私自身、今まで画像関連を中心にいくつかコンペ参加の経験はありましたが、レコメンドコンペ自体は初挑戦となりました。
当ブログでは、kaggleコンペティションに取り組んだ概要や予測手法など簡単にご紹介できればと思います。
1. Kaggle(カグル)とは?
Kaggleとは、データサイエンス・機械学習に関する世界最大のコミュニティ/コンペティションです。
参加者のレベル / 規模 / 認知度において、世界最大のデータ分析プラットフォームとしての地位を占めてます。様々な国の方が参加している為、コンペの説明や情報交換は主に「英語」となります。日本人の参加者もかなり多いです。
1-1 kaggleのフロー
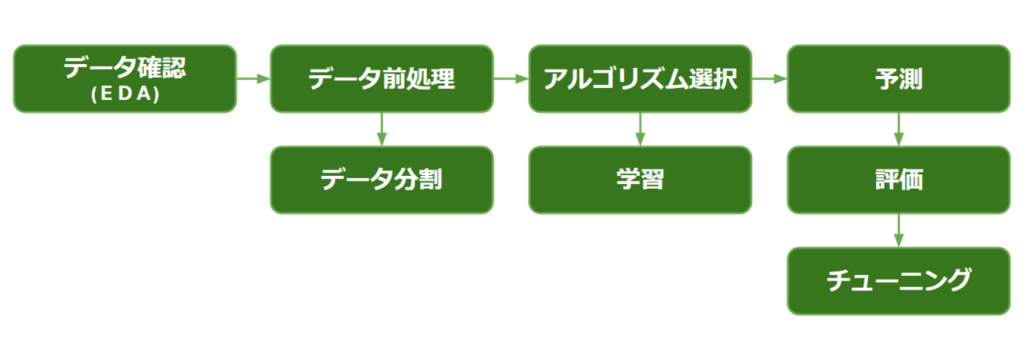
kaggleの一般的なフローは、以下の流れで進みます。
(用語補足)
【データ確認(EDA)】
データの欠損値/基本統計量/可視化等を行う。アルゴリズム(モデル)が精度を高めるうえでの情報を引き出すための作業
【データ前処理】
主にpandasを扱い、データをモデルが学習できる形に綺麗に整える
【評価】
trainデータ/validationデータ/testデータに分けて、 kaggle提出前に評価を行う(Cross Validation)
【チューニング】
特徴量エンジニアリング、モデルのパラメータ選定、モデル自体の変更・組み合わせなどを通して、予測精度を上げていく一連の作業
2. コンペティションでの取り組み
2-1 コンペティション概要
H&Mのオンライン購買データ等を使用し、各ユーザーごとのある1週間の購買商品の予測
| 対象期間 | ・2022/02/08~05/10 |
| 条件 | ・約130万人分の各顧客ごとのアイテムを最大12個まで予測する ・商品は服から小物まで10万アイテム |
| 提供データ | ・顧客テーブル.. 約130万人分の顧客データ ・商品テーブル..10万商品のデータ..商品idの他に商品ジャンル、商品の説明(テキスト)など25カラム ・購買テーブル..約3,000万回分の購買データ ・画像データ..10万アイテムのjpeg画像 |
当コンペの特徴はざっくりですが下記となります。
- テーブルデータの量が多く、高速化の工夫が必要
- ユーザー130万x10万アイテムのランキング問題となり、基本的に当てるのは困難なタスク(評価は最大1だが、金メダルでも約0.034~が目安となっていた)
- 画像やテキストデータもあり、手法の自由度が高い
2-2 予測手法のご紹介
[手法1] ベースラインで提出
以下2つの手法を組み合わせての予測
- ユーザーの直近の購買履歴で12個埋める
※12個に満たないアイテムは「下記2.」で埋める - 最人気アイテム
【スコア】 0.019 (2,000 / 3,000 位)
参考Notebook: H&M EDA and Prediction
[手法2] 共起/直近の人気アイテム
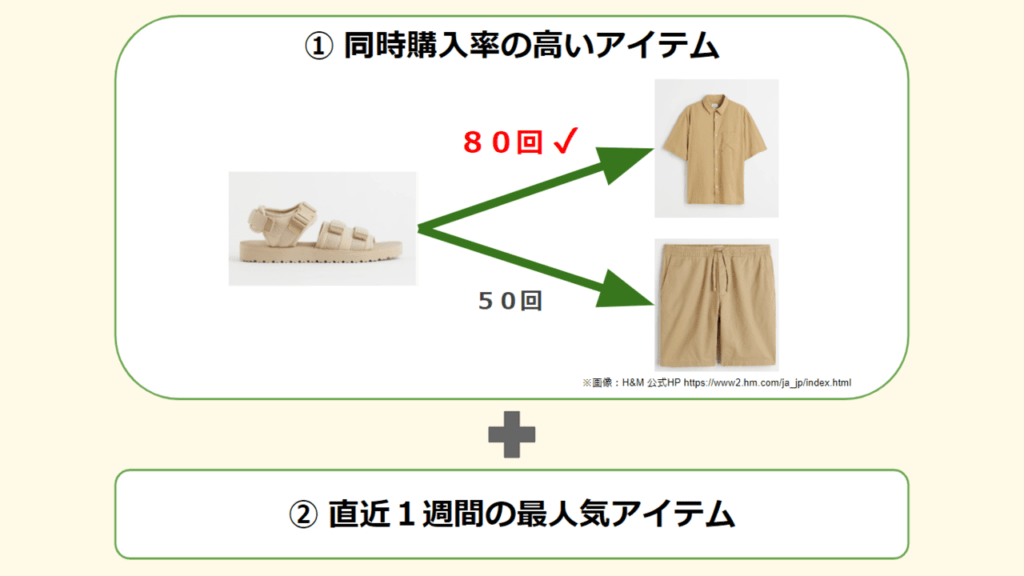
以下2つの手法を組み合わせての予測
- ユーザー履歴アイテムと同時購入率の高いアイテム
※1に満たないものは「下記2.」で埋める - 直近1週間のTop12アイテム
【スコア】 0.02143 (1,520 / 3,000 位)
参考Notebook:Recommend Items Purchased Together – [0.021]
[手法3] Sessionを考慮したモデル
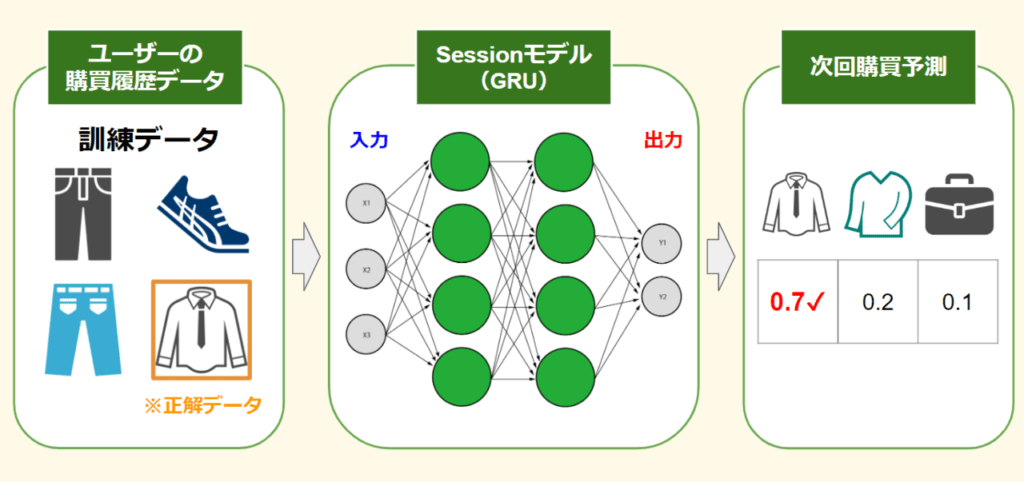
深層学習RNN系列のGRUを使った時系列(購買履歴の流れ)を考慮した予測モデル。以下の手順で実行
- 予測したいデータを正解データとして抜く
- GRUのSessionモデルで学習させる
- 学習済みモデルによる購買の予測
【スコア】 0.02103 (1,600 / 3,000 位)
参考Notebook:Recbole:LSTM/sequential for recommendation tutorial
モデル詳細(論文):SESSION-BASED RECOMMENDATIONS WITH RECURRENT NEURAL NETWORKS
(その他に検討した予測手法)
| LGMB | コンペ開催途中にて、今回のメイン解法となっていた。自身では実装まで手を付けられず。 |
| ユーザーベース協調フィルタリング | 計算コストが高く、高速化をしないといけない壁で自身では進めず。他分析者にて「単純使用だと効果的では無い」との記載もあり中断。 |
| アイテムベース類似度推薦 | 社内案件に近かったため調査。単体利用より他と組み合わせて使う場合が殆ど。 |
3. コンペティション結果と振り返り
3-1. コンペ結果
▼最終順位
【スコア】 0.02103 (1,600 / 3,000 位)
金メダルは0.0345〜、 銀メダルは0.02587、 銅メダルは0.02397 となりました。
数値上でのパッと見では僅差ですが、0.001上げる為には様々な工夫・レコメンド関連の理解が要求され、見た目以上に差がある数値となっています。
結果として上位争いは遠く、内容的にもコンペの中でフローサイクルをうまく回せなかった悔しい結果となりました。
3-2. コンペフロー振り返り / 反省点 / 収穫
フローでの反省点
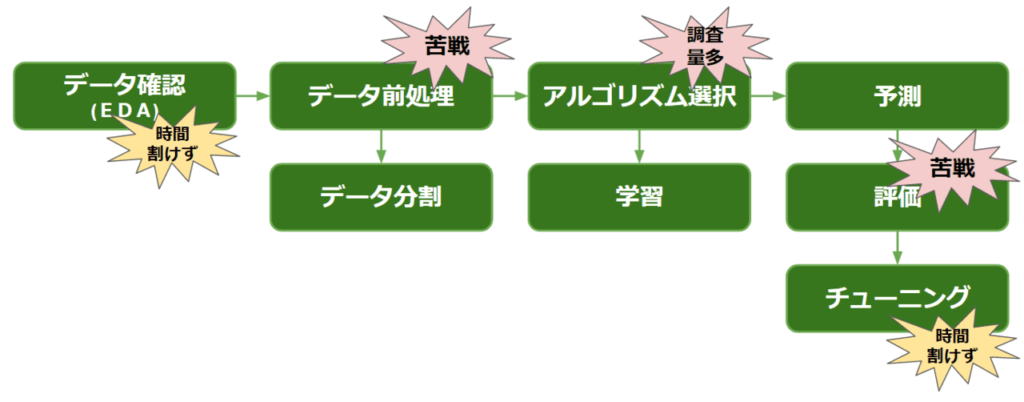
「Pandas(パンダス)の操作や評価の理解に苦戦」→「アルゴリズム調査に時間をかけ過ぎた」→「EDAとチューニングに時間が割けず」→「精度向上のサイクルを回せなかった」ことです。また、慣れていない手法に広げ過ぎたのも、提出のサイクルを遅らせる要因となってしまいました。
コンペ参加での収穫
前処理の習熟度向上、レコメンドの基本的な手法の理解、一連のレコメンドモデルの分析フローの実体験ができたことだと感じております。
おわりに
今回のkaggleコンペティション参加にて、自身の力不足を痛感する悔しい結果となりました。データサイエンティストとして、レコメンドという分野における専門性と分析サイクルを回すうえでの技能(前処理 / CV評価 など)の習熟が特に課題となりました。
悔しい結果とはなってしまいましたが、業務の中でkaggleコンペに挑戦する機会をいただけたのは非常に有難かったです。今回のコンペを通して、レコメンドに関する基本手法や他のデータサイエンティストたちの実際のコード等を幾つか学べたので、うまく社内の案件等に活かしていきたいと思います。



