画像生成AIと拡散モデルについて

こんにちは。データサイエンス課のブログ担当です。
2022年現在、「画像生成AI」といった技術がAI界隈で話題となっております。
当領域に関しては期待や課題など賛否両論ありますが、AI技術としては確固たる分野を築き始めているかと思います。今回はそんな「画像生成AI」を使用した感想やその仕組みについてご紹介できればと思います。
画像生成AIサービス
現在、画像生成AIで有名なサービスといえば「Midjorney(ミッドジャーニー)」や「Stable Diffusion(ステーブル・ディフュージョン)」が挙げられます。
メディアにも頻繁に取り上げられているので、ご存じの方が多いかと思いますが、キーワードに合った画像を短時間かつ高精度で作成してくれる画像生成サービスになります。
画像生成サービスを実体験
今回は「Midjourney(ミッドジャーニー)」を実際に利用してみました。
好きなお題(作りたい画像のイメージ文章)を与えると、自動的にものの数秒で画像を生成してくれるサービスです。※入力する文章は英語表記
実際に「red color blackhole shining in the universe(訳:宇宙で輝く赤色のブラックホール)」といったキーワードで作らさせた画像がこちらです。

とてもアーティスティックでプロデザイナーが描いたような画像が数秒で生成され驚きました。
続けて、”花”や”咲き誇る”のイメージである弊社ロゴの意味に近しいキーワードで生成してみたものが下記右側の画像となります。

キーワード:blue and yellow gourgeous flower which is anime style in the night(訳:夜の中のアニメ風の青・黄色の豪華な花)
似たような花を作成してくれましたが、想定していたものよりは少々リアルなテイストになってしまいました。英語の指示が悪かったのか、アニメ風の表現が反映されなかったようです。
『著作権』についての議論
Midjourneyなどの既成サービスを使えば、大量に質の高いアートを作成することができます。
しかし、その場合の「著作権」について現在議論となっており、主に「自動生成された画像に著作権が発生するか?」という法的な視点での議論がなされています。Midjourneyの場合は基本的に所有者は「生成したユーザー」であるとしています。ただ、今後こういったサービスに法的に規制が掛かる可能性があるかもしれません。
画像生成AIの基盤となる「生成モデル」
上記のような画像生成サービスを支えているのが「生成モデル」です。
生成モデルとは、集められた訓練データを学習し、それに似たデータを生成できるモデルです。
訓練させたデータが画像データならば、「画像生成モデル」となり、訓練データが音声なら「音声生成モデル」となります。その中で有名な技術として「GAN」や「VAE」といったものがあります。以下にて「GAN」について簡易的にご紹介します。
生成モデル:GAN
GAN(Generative Adversarial Network)では、「Generator」「 Discriminator」といった2つのブロックが互いに競争し合いながら学習し、本物に近い画像データを生成させるモデルです。
「Generator」 のタスク:本物そっくりの画像(猫)を生成する
「Discriminator」のタスク:偽物の画像(猫)と本物の画像(猫)を見分ける
ざっくりとですが、GANの学習フローとしては以下1~4の流れで学習を進めます。
【1】 Generatorにランダムノイズを入力し、Generatorはランダムノイズを再現する。
【2】 DiscriminatorはGeneratorの作成した偽画像と本物の猫画像を分類し、本物をきちんと分類できるように学習する(偽物を本物としたらペナルティが与えられる)
【3】 GeneratorはDiscriminatorが間違える(騙せた)ように、偽物の精度を上げていく。
【4】 両者の学習を進め、Generatorは本物にそっくりな画像を生成したら学習は成功
★猫の画像例★


このように、GANは生成モデルの代表的技術として、本物に非常に近い画像を生成できることで有名でした。
ただ、GANの課題として、高解像度のデータセットの作成にあたり学習が難しいという欠点が指摘されていました。
それを補う形で登場してきたのが「拡散モデル」と呼ばれるものです。拡散モデルではこれらの課題を克服できることが示され、高解像度のデータの作成技術が進歩した形になります。
拡散モデルについて
拡散モデルについて、技術的な細部の説明をしてしまうと長くなってしまうので、今回は概要・要点に絞ってご紹介します。
★説明すること★
- forward processの概要
- reverse eprocessの概要
(説明しないこと)
- 学習時の最適化について(変分ベイズ推論, KLダイバージェンスの詳細)
- ガウス分布、ガウシアンノイズ、マルコフ連鎖などの概念
- 画像生成モデルと言語モデルとの関係(Text EncodeとImage Encodeの結合)
※簡略化した説明の点、ご了承ください。こちらの詳細な理論・数式について気になる方は、原論文や参考サイトなどをご参照ください。
拡散モデルの概要
ひとことで表現すると、拡散過程で画像を生成するといった生成モデルの「新しい手法」です。
徐々にガウスノイズを足していく過程(forward process)と、反対にガウスノイズを取り除く過程(reverse process)を通した画像の生成を行います。
拡散(かくさん)とは?
「拡散」とは、物理学から持ち込まれた概念です。原子・分子のような小さな粒子が周囲に拡散していく現象をモデルに取り組んだので、拡散モデルと呼ばれています。


上の拡散のイメージのポイントは、時間を巻き戻せば拡散する前の綺麗な状態を復元できることにあります。
より専門的な用語で説明しますと、マルコフ連鎖の中でガウスノイズを付加していく部分で”拡散”を表現したものが拡散モデルです。
こちらが拡散モデルによる画像生成の全体像です。
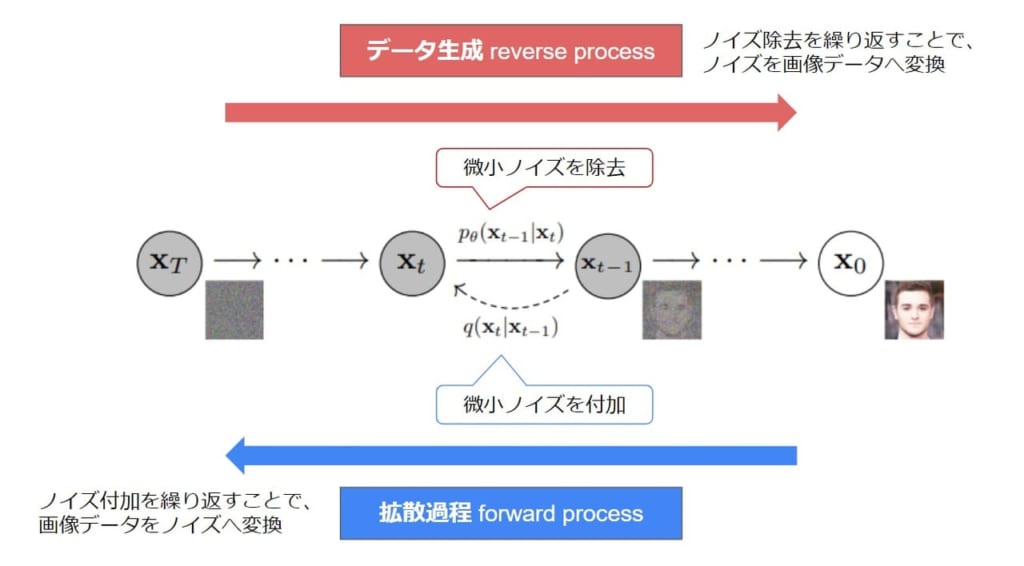
ノイズを「付与」「除去」する2つの過程
拡散モデルでの画像生成の過程にて、ノイズの付与とノイズの除去の2つのプロセスについてご紹介します。
一部数式を使用した部分があるので、こちらに関しては興味・必要性に応じてご覧下さい。
■ forward process
Forwatdプロセスは徐々にノイズを足していき、最終的にノイズ画像を作ることが目的です。
要点としては以下となります。
- 状態Xt-1にガウシアンノイズを付加して、次の状態Xtに遷移させる
- ノイズの強さをパラメータβとする(※ハイパーパラメータ)
- 状態遷移は条件付き確率q(xt| xt-1)で表す
- 初期状態のx0は確率分布qからサンプルされる(※ベイズ推定で確率分布qを決める)
上の説明を関数で表現すると以下になります。
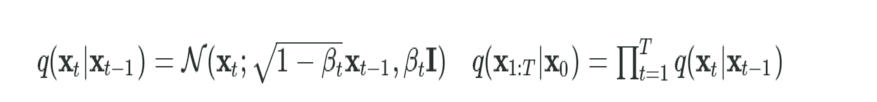
←左の方程式(1つ先の状態に進む確率)
- ある状態のTステップ(T回時間が進む時)の状態Xt が前の状態Xt-1で表されます
→右の方程式(長い間隔で左の方程式を繰り返したときの状態へ進む確率)
- 初期時X0からTステップが経過した後のX1:Tについて、遷移確率q(xt|xt-1)の総乗(全ての状態をかけ算した合計)で表します。
- つまり、各ステップの遷移確率q(xt|xt-1)の合計を計算することで、長い間隔での時間が経過したあとの状態の確率を求めています。
以下が1ステップごとにノイズを付加するイメージです。

このステップを繰り返す事で画像にガウスノイズが徐々に付加されて、最終的にただのノイズになります。
■ reverse process
次はノイズを復元していくreverseプロセスをご紹介します。
要点としては以下となります。
- forwardのノイズを付加するプロセスなのでノイズを除去していくプロセスを表現できれば、データを生成できる
- 状態遷移はforward processとは逆にp(xt-1| xt)で表す
- 復元の際にもforwardの逆なのでガウシアンノイズを用いてノイズを除去する
- p(xt-1| xt)はβt(ノイズ付加時の変化量)が十分に小さいとガウス分布に従うので、ノイズの除去も再現できる
- データセット全体を使って条件付き確率を推定するPθを学習する
上の説明を関数で数式で表現すると以下になります。
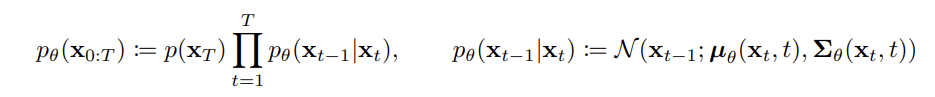
※記号の説明 Xt →時間Tまで画像のノイズ付加後 / X0 → 画像のノイズ付加前
最初に右側の方程式から説明します。
右の方程式(1つ前の状態に戻る確率)
- 1つ前に戻る(1ステップ)の状態遷移を条件付き確率pθ(xt-1|xt)で表す
- 状態遷移pθ(xt-1|xt)は条件付き確率のパラメータθのもとでガウシアンノイズからサンプリングを行う。
- パラメータθはガウス分布(=forwardで加えたガウシアンノイズ)の平均μと分散Σに該当する
左の方程式(長い間隔で右の方程式を繰り返したときに元の状態に戻る確率)
- スタートxt,から xt-1, xt-2, ….とx0ゴール(復元した画像)までの時刻で、各状態間の遷移の合計をpθ(xt-1|xt)の総積で表す(以下)
- pθ(xt-1|xt)の総積とp(xt)をかけて、最後の状態(復元した画像)を求める。
- 復元を繰り返す中で、ノイズを除去できるようにパラメータθ(平均、分散)を学習する
- つまり、うまくノイズから画像を復元できるように、ノイズを除去するガウス分布の平均と分散を推定することが、reverse processでの学習の目標になります。

以上が「forward process」と「reverse process」の概要となります。学習・最適化の手法など多くの部分を割愛しておりますので、実際はこの他にも様々な方法が存在します。
おわりに
▼生成モデルの次の領域・展望
Midjourneyを作成した企業をはじめ、先端領域では動画の生成モデル・音声コンテンツの生成モデルに対して拡散モデルの適用・商用開発を行っている情報があります。多くの技術的課題はあるものの、拡散モデルによるデータ生成のポテンシャルが期待されているので、音楽や動画に関しても近いうちに同様のクオリティの製品ができてくる可能性はあります。
Googleでは既にテキストから短い動画の自動生成に成功しています。今後、短いCM・広告動画の作成に関して、生成モデルが進出していく可能性は大いにありそうです。クリエーターの作業を助ける観点で、手軽で応用性の高い分野が出てくることに期待したいです。



